수강하고 있는 수업에서 학기 말에 CS224n 관련 발표를 하게 되어서 관련 글을 작성해보려고한다.
스탠포드 대학의 크리스토퍼 매닝 교수님의 CS224n: Natural Language Processing with deep learning 강의를 많이 참고하여
일부분을 작성 및 정리하였다.
https://youtube.com/playlist?list=PLoROMvodv4rMFqRtEuo6SGjY4XbRIVRd4&feature=shared
Stanford CS224N: Natural Language Processing with Deep Learning | 2023
Natural language processing (NLP) is a crucial part of artificial intelligence (AI), modeling how people share information. In recent years, deep learning ap...
www.youtube.com
강좌 자체가 길지만 시간은 별로 없어서 아래의 사항들은 좀 제외하고 정리해두었다.
1. 다른 딥러닝 강의에 나오는 부분 [Backpropagation, GD, SGD, 기타 등등]
2. 너무 깊게 들어간 증명
목차의 구성은 총 6장으로 정리해두었으며 Introduction 글 작성 기준으로 아직 Word Embedding 까지만 작성하였다.
목차
- Introuction
- Word Embedding
- Syntatic Structure & Dependency Parsing
- Recurrent Neural Networks & LSTM RNNs
- Translation, Seq2Seq, Attention
- Self-Attention and Transformer
이번 장 목표
- NLP 란 무엇인지 대략 알 수 있다.
- Computer에 자연어를 표현하기 위한 방법을 알 수 있다.
- denotational semantics과 distributional semantics를 구분할 수 있다.
What is Natual Language Process?
NLP가 무엇인고 하면서 검색해보면 IBM 홈페이지에서 아래와 같이 설명한다.
https://www.ibm.com/topics/natural-language-processing
What Is Natural Language Processing? | IBM
Natural language processing enables machines to understand and respond to text or voice data.
www.ibm.com

Natural language processing, or NLP, combines computational linguistics-rule-based modeling of human language-with statistical and machine learning models to enable computers and digital devices to recognize, understand and generate text and speech.
자연어 처리 또는 NLP는 컴퓨터 언어학[인간 언어의 규칙 기반 모델링]과 통계 및 기계 학습 모델을 결합하여 컴퓨터와 디지털 장치가 텍스트와 음성을 인식, 이해 및 생성할 수 있도록 합니다.
뭔소린가 싶지만 아래의 내용이라고 생각하면 좋을 것 같다.
"기계가 사람의 언어를 이해하고 해석하며 이를 통해 다양한 애플리케이션, 서비스에 활용되는 기술"
이러한 NLP를 이용한 애플리케이션은 다양하다.
- 하나의 언어에서 다른 언어로의 번역
- 음성 명령에 대한 인식/반응
- 많은 양의 텍스트를 요약
- etc
뭔가 예시를 들자면
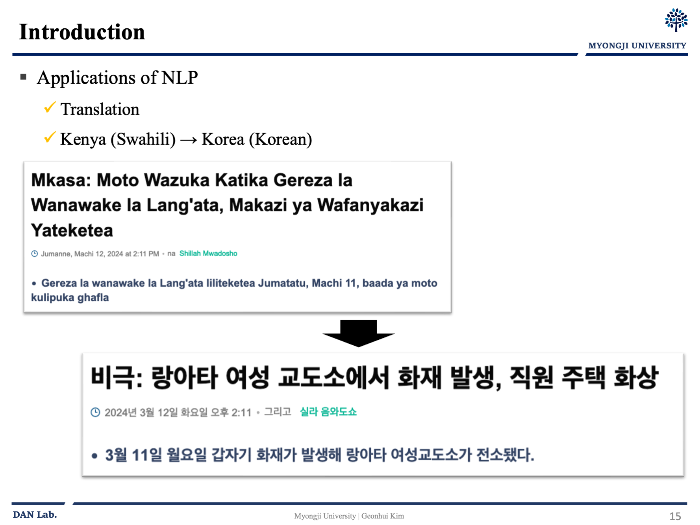
나는 스와힐리어에 대해서 하나도 모르지만 오늘날의 기계 번역은 어떤일이 벌어졌는지 알 수 있도록 해준다.
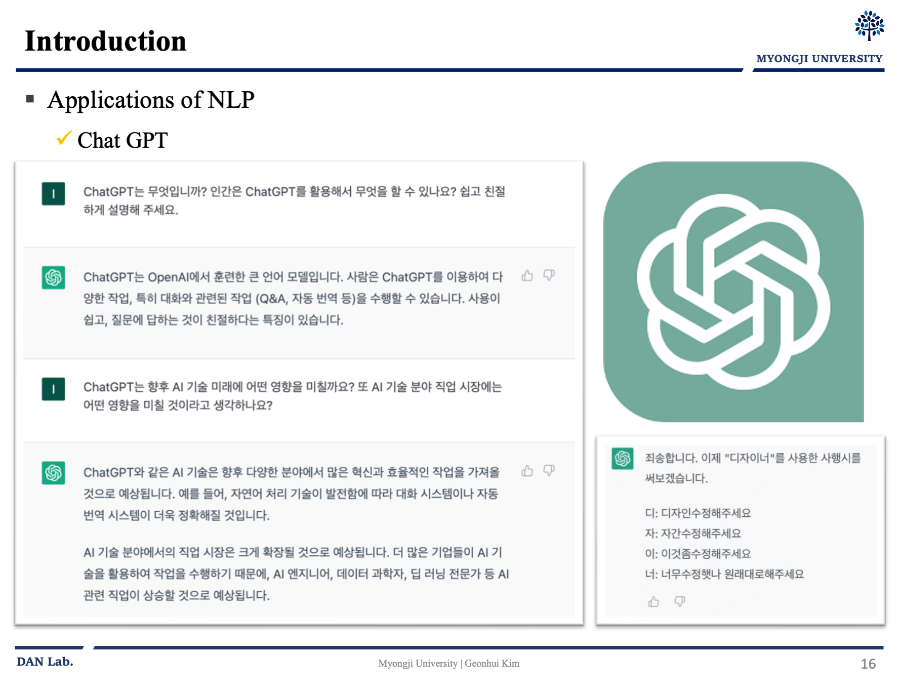
그리고 오늘날 엄청난 성공인 NLP 애플리케이션 중 하나인 Chat GPT를 통하여 많은 부분에서 도움을 받고 있다..
하지만 NLP의 이러한 엄청난 기능들은 하루 아침에 일어난 것이 아니다.
그러니 우리는 먼저 가장 처음 단계인 어떻게 사람의 단어를 컴퓨터[기계]에게 표현할 것인지 알아보자
Denotational Semantics [표시적 의미론]
인간의 언어를 모두 컴퓨터에 모두 표현하기 전에 조금 쪼개보자.
우리는 단어의 "의미"를 어떻게 표현할까?
보통은 사전의 형태로 표현한다. 사전은 어떻게 표현되어 있을까 웹스터 사전에서 meaning의 뜻을 찾아보자.
처음에 meaning이라는 큰 글씨가 있고 그 밑에 이것이 무엇인지에 대한 설명이 적혀있다.

- the thing one intents to convey especially by language
- the thing that is conveyed especially by language
- something meant or intented
- ...
Signifier(Symbol) <-> Signified(Idea, Thing)
사전에서처럼 어떤 Signifier[symbol, 기호] 와 이에 대한 Signified[idea, thing] 에 대한 방식으로 단어를 표현하는 방식을Denotational Semantics [표시적 의미론] 이라고 한다.
그럼 이런 표시적 의미론을 어떻게 컴퓨터에서 사용할까?
흔한 NLP Solution 은 WordNet이다.
WordNet은 프린스턴 대학에서 구축한 Thesaurus[유의어, 어휘] DB이다.
동의어 집합 및 Hypernyms["is a" relationships] 들을 담고있다
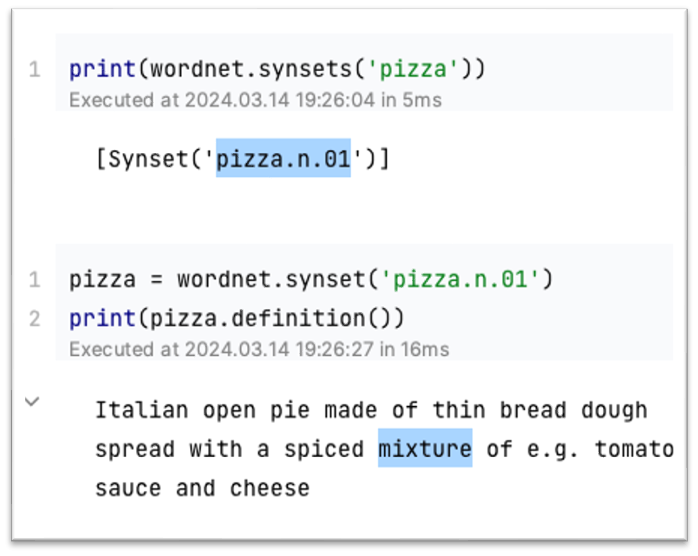
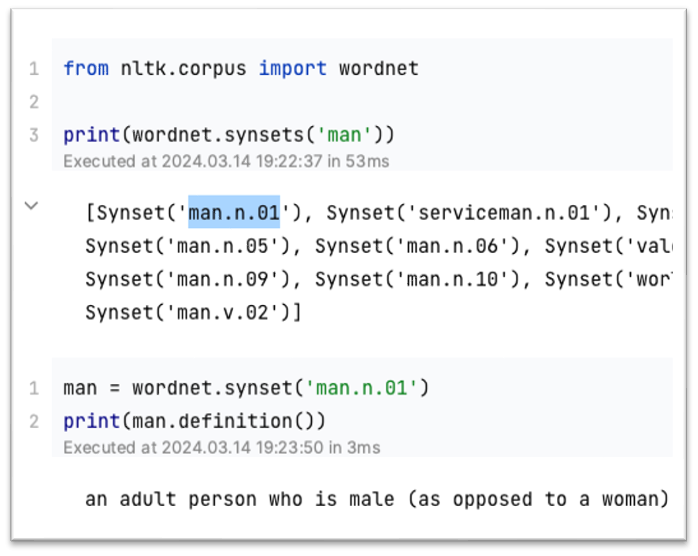
이런 사전 형태로 나타내어진 표현법은 아주 좋은 리소스이다.
하지만 아래와 같은 큰 문제들이 존재한다.

1. 리소스로서는 훌륭하지만 뉘앙스가 부족하다
무슨 말이냐면 예를들어 proficient 와 good은 synonym[동의어] 로 나열될 떄가 있다.
하지만 완전히 같은 뜻은 아니며 특정 문맥에서만 맞는 이야기다
2. 신조어나 slang 과같은 새로운 단어에 대한 문제 [Incompleteness]
새로운 단어에 대응하기 위해서는 사람의 노동력이 들어갈 뿐더러, rizz, swiftie, 쓴배임 등
신조어나 슬랭에 대해서 최신 사항으로 대응하기에는 사실상 불가능하다.
3. 주관적이다.
4. 단어간의 유사성을 계산할 수가 없다.
가장 큰 문제다. 슬라이드 그림과 같이 사전 형태로 나누어진 단어 표현은 단어들간의 유사성을 계산할 수가 없다.
왜일까?
Discrete Symbols
Denotational Semantics 는 discrete symbols [분산된 기호] 형태로 나타내어지게 된다.

표시적 의미론과 같이 전통적인 NLP에서는 우리는 단어를 분산된 기호 형태로 주로 표시해왔다.
한번 분산된 형태로 표현할 때 어떻게 표현하는지 봐보자

분산적으로 표현하기 위해서 우리는 단어의 수 만큼의 vector[혹은 배열] 차원을 만들고 해당 되는 단어는 1로 표시 나머지는 0으로 표시하는 방법을 사용할 수 있을 것이다.
이를 One-hot vector 라고 한다. 위의 그림처럼 motel이라면 [1, 0, 0] 이런 식으로 표기된다.
아래의 특징을 가진다.
- 단어의 종류 = 차원의 수
- e.g., 겹치지 않는 단어 개수가 500,000개라면 차원도 500,000차원이 될 것이다.
- 단어 벡터간의 관계가 orthogonal 하다
- 우리가 만약 여행을 가야해서 시애틀 호텔을 검색하면 시애틀 모텔도 찾고싶지만 이 두 단어간에는 직교하기에 아무런 관련성이 없다.
- 뭔가 특별한장치를 한다고해도 이 두 단어간의 자연스러운 유사성 개념이 없다.
해당 문제를 해결할 수 있는 방법은 뭘까?
먼저 생각해볼 수 있는 것은...
- WordNet 동의어 목록에 의존하여 유사성 얻기
- 잘 알려진 실패하는 방법이다 왜냐하면 imcompleteness 때문에!
- 벡터 자체의 유사성을 인코딩하는 방법을 배우기 -> Distributional semantics
Distributional Semantics
단어의 뜻은 주변에 자주 등장하는 단어에 의해서 주어진다는 아이디어에서 출발한다.
현대 통계 NLP의 가장 성공적인 아이디어 중 하나이다.
단어 w가 텍스트에 나타날 때, 그 단어 근처에 나타나는 문맥 단어들을 통하여서 w의 표현을 구축한다.
어떤 느낌인지 모를 수도 있으니 좋은 예제가 있어서 가져왔다.
A bottle of tezgüino is on the table
Everyone likes tezgüino.
Tezgüino makes you durnk.
We make tezgüino out of corn
우리는 tezgüino 라는 것이 무엇인지는 정확히는 모르겠지만
이것이 음료이면서 알콜이 들어갔으며 옥수수로 만들어진다는 사실을 알 수 있다.
이러한 아이디어를 이제 다음 목차인 Word Embedding 에서 어떻게 솔루션을 만들었는지 살펴보자
'AI,ML' 카테고리의 다른 글
| NLP - [3] LSTM RNN (1) | 2024.09.23 |
|---|---|
| NLP - [2] Language Model, RNN - (3) (0) | 2024.07.21 |
| NLP - [2] Language Model, RNN - (2) (0) | 2024.06.21 |
| NLP - [2] Language Model, RNN - (1) (1) | 2024.06.17 |
| NLP - [2]Word Embedding (0) | 2024.03.29 |


