Model heterogeneity 한 상황에서의 연합학습을 어떻게 할지에 대한 논문이다. 논문의 출처는 다음과 같다. 그냥 목차별로 쭉 읽은 내용을 적어두려고 한다. 논문의 출처는 다음과 같다.
https://arxiv.org/abs/2010.01264
HeteroFL: Computation and Communication Efficient Federated Learning for Heterogeneous Clients
Federated Learning (FL) is a method of training machine learning models on private data distributed over a large number of possibly heterogeneous clients such as mobile phones and IoT devices. In this work, we propose a new federated learning framework nam
arxiv.org
1. Introduction
Introduction에서 나온 배경 설명으론 일반적으론 하나의 global model을 추론하기 위해서 로컬 모델이 글로벌 모델과 동일한 아키텍처를 공유한다는 가정을 수행한다. 이는 가장 computing resource가 좋지 않은 클라이언트가 데이터를 학습할 수 있도록 글로벌 모델의 복잡성을 제한해야한다고 한다. 그러면서 실제로 각 클라이언트의 computation, communication capability는 모두 다르므로 이를 의미하는 이기종 클라이언트를 다루는 것이 연합학습에서 중요한 점이라고 한다.
논문에서는 다양한 computationg 복잡성을 가진 이질적인 로컬 모델을 훈련하면서 하나의 글로벌 추론 모델을 생성할 수 있는 연합학습 프레임워크를 제안한다. heterogeneous local model을 안정적으로 학습하는 것은 쉽지 않으므로 제안 기법은 이를 해결하는 것이 핵심 요소라고 한다. 이를 위한 contribution은 다음 세가지이다.
- Model heterogeneity의 가능성을 파악하고 이질적인 로컬 모델을 훈련하고 이를 하나의 글로벌 모델로 안적적으로 통합할 수 있는 프레임워크. (추가적인 계산 오버헤드 없이)
- 제안 솔루션은 다양한 비율의 클라이언트가 distinct capabilities를 가지는 환경을 다루며, 그 결과 모델의 이질성이 동적으로 변하더라도 프레임워크의 학습 결과가 여전히 안정적이고 효과적이라는 것을 보여줌
- FL 훈련을 개선하기 위한 몇가지 전략을 소개하며 balanced non-iid 통계적 heterogeneity에 robust 하다는 점을 증명함. 또한 실험 연구 수행
2. Related Works
다양한 연구 분야에 대한 소개를 하고 있음. 해당 블로그 글에서는 따로 쓰지는 않겠다..
3. Heterogeneous Federated Learning
3.1 Heterogeneous model
먼저 연합학습에 대한 기본적인 설정에 대하여 설명한다. 연합학습(Federated Learning, FL)은 $m$ 개의 클라이언트에 걸쳐서 로컬에 분산된 데이터 $\{ X_1,...,X_m \}$에서 global inference model을 학습하는 것을 목표로 함. local model parameters $\{ W_1,...,W_m \}$. 서버는 로컬 모델 파라미터를 수신하여 평균화를 통해 글로벌 모델 $W_g$로 집계됨. 해당 프로세스는 여러개의 통신 라운드로 반복되고 $W_{g}^{t}= \frac{1}{m} \sum_{i=1}^{m} W_{i}^{t}$로 수식으로 나타낼 수 있음 여기서 $t$는 iteration. iteration $t$에서의 글로벌 모델 $W_t$는 subset of local clients에게 전송되고 다음 라운드의 로컬 모델은 $W_{t}^{t+1}=W_g^t$로 나타낼 수 있음.
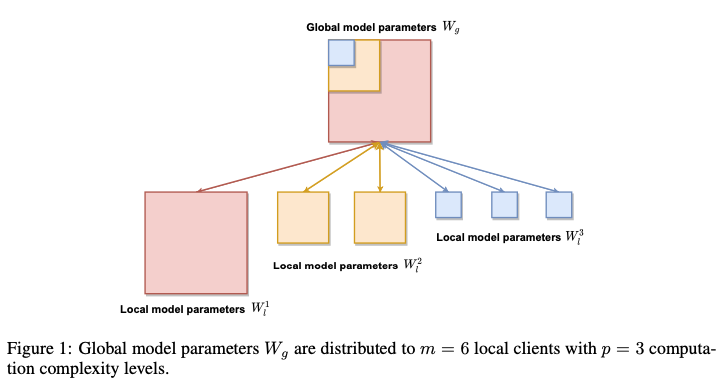
FL의 기본적인 작업은 글로벌 모델과 로컬 모델이 동일한 아키텍처를 공유한다는 가정을 둔다. 제안 기법은 이런 걸 relaxation 하는걸 초점을 둔다고한다. 로컬 클라이언트의 계산 및 통신 복잡상을 줄이는 것이 주된 동기. 글로벌 집계와 로컬 업데이트를 단순화하기 위해서는 로컬 모델 파라미터를 글로벌 모델 파라미터의 하위 집합으로 만드는 방식은 ($W_{i}^{t+1} \subseteq W_g^t$) 하위집합을 선택하는 최적의 방법이나 모델 아키텍처 호환성, 기존 FL 프레임워크의 수정 등 몇가지 새로운 issue를 일으킴. 딥러닝 모델 맥락에서 이런 문제를 해결하기 위해서 HeteroFL을 개발했다함.
다음은 글로벌 파라미터 $W_g$ (단일 은닉층에 대해서 $W_g \in \mathbb{R}^{d_g \times k_g}$ , 여기서 $d_g$ 와 $k_g$는 출력 채널 크기와 입력 채널 크기) 를 하위 집합으로 선택하는 방법을 설명함. Fig 1에서 보여지는 것처럼 여러 computation complexity를 가지는 하위 파라미터 집합을 다음과 같이 정의한다고함. $W_{1}^{p} \subset W_{1}^{p-1} \subset ... \subset W_1$.
여기서 하위 집합으로 선택한다는 의미는 글로벌 모델에서 일부만을 로컬 모델을 사용하는 즉 예를들어 신경망의 폭을 줄여서 학습하는 방식을 의미하는 건가? 싶다. 일단 계속 일어봐야할 듯
- hidden channel shrinkage ratio $r$
$r$을 이용하여 은닉층의 출력 채널 크기글 조정한다고 함. $d_l^p = r^{p-1}d_g$
그에 따라 로컬 모델 파라미터 $W$의 크기는 $|W^p|=r^{2(p-1)}|W_g|$ 가 되고 모델의 축소비율 $R$은 $R=\frac{|W^p|}{|W_g|}=r^{2(p-1)}$로 정의됨
이런 구조를 통해서 로컬 클라이언트의 계산 능력에 따라서 글로벌 모델 파라미터의 하위 집합을 적응적으로 할당한다. 예를 들어 계산 복잡성 레벨 $m_1,...,m_p$에서 클라이언트 수가 정해딘다면 다음과 같은 방식으로 글로벌 집계를 수행한다고 한다.
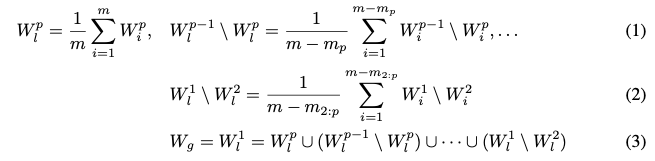
여기까지 읽어 봤을 때 내용을 이해한 바로는 결국 $p$ 개의 하위 집합의 갯수를 정하고 시작하는 것 같다. 또한 집계의 식 (1) 오른쪽, (2), (3)이 나타내는 바는 $p-1$ 레벨에서 p레벨로 축소되는 동안 제거된 파라미터들의 평균값을 계산하는 것이라고 이해된다. 이는 결국 최종적으로 간단한 모델에서 복잡한 모델로 한단계씩 올려서 집계하는 것으로 보인다.
일단 밑에를 읽어봐야겠다.
우선 표기 편의를 위하여 iteration index $t$ 를 드롭했다. 또한 $W_i^p$를 matrix/tensor로 표기한다고한다. 여기서 matrix/tensor라는건 그냥 가중치 텐서(또는 행렬)을 나타낸다고 보면 될 것 같다. 그리고 $W_g^t[:d_m, :k_m]$는 텐서에서 행렬의 특정 부분(submatrix)를 나타낸다. $d_m$, $k_m$의 차원을 가지며 결국 이는 각 서브트리는 복잡성에 따라 $W_g^t$의 좌측 상단을 기준으로 일부만을 사용한다는 뜻이다(uppder left submatrix). 마지막으로 $W_g^{p-1, t+1} \backslash W_g^{p, t+1}$은 set of elements 를 나타내는데 이는 $W_g^{p-1, t+1}$를 포함하고 $W_g^{p, t+1}$을 제외한다.이는 결국 $W_g^{p-1}$과 $W_g^p$ 사이의 가중치 차이를 나타낸다. 정리하자면 예를들어 10x10의 매트릭스가 있고, 세계의 그룹으로 나눈다면 (10x10, 5x5, 3x3, 클라이언트 수 5, 3, 2개) 레이어의 집계는 다음과 같은 단계로 집계한다고 이해했다.
레벨 3의 가장 작은 파라미터 부분만 사용한 클라이언트의 학습 결과를 집계 10x10, 5x5, 3x3은 모두 3x3 영역을 가지니까 10개라서 10으로 나눔, 이후 레벨 2의 두번째 파라미터 부분만 이용한 학습 결과 집계 3x3 은 5x5 부분이 없으니까 제외하고 10x10의 파라미터를 가지는 클라이언트의 5x5 부분과, 5x5 파라미터를 이용하니까 8로 나눔, 마지막으로 10x10 로컬 모델을 학습은 5로 나눈다. 5x5 와 10x10 부분을 집계할 때 5x5의 경우 3x3 영억을 제외하고, 10x10은 3x3과 5x5 영역을 제외하고 집계를 수행하는 것 같다. 그래야 합집합을 했을때 두번 나오는 부분이 없으니까...
$W_g^{p-1, t+1} \backslash W_g^{p, t+1}$ denotes the set of elements included in $W_g^{p-1, t+1}$ but excluded in $W_g^{p, t+1}$
뭐 이렇게 하는 방식이 소규모 로컬 모델이 대규모 로컬 모델의 파라미터에 일부에 대해 글로벌 집계를 덜 수행하므로서 글로벌 집게를 통해 더 많은 이점을 얻을 수 있다고 한다. 경험적으로 봤을때 이 접근이 각 클라이언트 또는 계산 복잡성 수준에 대해 균일하게 샘플링된 subnetwork보다 더 나은 결과를 생성한다고 한다.
3.2 Static Batch Normalization
일반적으로 딥러닝 학습에서는 Batch Normalization (BN)을 채택하여 최적화를 용이하게 하고 안정화를 시키나, FedAvg와 같은 대부분의 연합학습 시나리오에서는 BN을 피한다. 이는 BN이 모든 히든 레이어에서 표현의 추정치를 실현한다고 한다. 다시말하면 각 히든 레이어에서 데이터를 정규화하기 위해서 평균과 분산 값을 업데이트한다. 그리고 이런한 통계를 서버에 업데이트하게된다면 더 많은 통신 비용과 개인 정보 보호 문제가 발생하기 떄문이다. Abdreux et al. (2020)에서는 통계를 로컬에서만 유지하는 방식을 제안한다.
해당 논문에서는 이기종 모델을 최적화하기 위해 정적 배치 정규화(Static Batch Normalization, sBN)이라 명명된 BN을 사용한다고 한다. 훈련 단계에서 sBN은 단순히 batch data만 정규화한다고한다. 로컬 모델의 크기도 동적으로 달라질 수 있으므로 로컬 모델의 통계도 추적하지 않는다고한다. 해당 방법은 독립적으로 HeteroFL에 적절하다고 한다. 훈련과정이 끝나면 서버는 로컬 클라이언트는 순차적으로 쿼리하여 글로벌 BN 통계를 누적적으로 업데이트 한다고 한다. 현재 문제는 글로벌 통계를 누적으로 계산하면서 개인정보 보호문제가 발생한다고 하는데 이는 향후 작업에서 해결한다고한다.
해당 챕터에 대해서 이해한걸 정리하자면
1. 연합학습
- 연합학습은 여러개의 클라이언트가 자신의 데이터를 로컬에서 학습하고, 글로벌 모델로 집계함. 개인 데이터는 로컬에만 존재하며, 통신 비용과 프라이버시가 매우 중요한 문제임
2. 기존 BN의 문제점
- BN은 각 batch에서 mean과 variance를 계산하며, 이를 정규화 하여서 사용함. 모델이 학습되는 동안 각 레이어의 running statistics를 계속 추적해야 함.
- 클라이언트마다 데이터 분포의 이질성으로 통계가 다르게 계산됨.
- BN의 통계를 서버에 업로드시 서버의 통신 비용 증가
- 통계는 데이터의 분포를 간접적으로 드러낼 수 있으므로 프라이버시 위험이 존재.
3. sBN
- running statistics 생략, 단순히 현재 배치의 mean, variance로 정규화 수행
- Running statiscs를 추적하지 않기 때문에 동적으로 변하는 모델의 크기도 유연하게 대응 가능.
- 학습이 끝난 후 서버가 클라이언트에 순차적으로 질의하여 bn통계를 누적, 프라이버시 문제가 있을 수 있음
3.3 Scaler
HeteroFL 프레임워크는 여러 에포크에 따라 모델을 최적화 해야하므로 모델의 복잡성 수준이 달라지면 로컬 파라미터는 다양한 스케일에서 벗어날 수 있다. 논문에서 말하는건 결국 여러 복잡도 수준에 따라 다른 로컬 모델들이 연속적으로 학습되는 과정에서, 각각의 로컬 모델 파라미터 값들이 서로 다른 규모로 변화하는걸 의미하는 것 같다. 이런 현상을 기존에는 dropout 방식을 사용해서 훈련 단계에서 탈락률 $q$ scale 표현을 $\frac{1}{1-q}$로 사용한다. dropout의 경우 일반적으로 마스킹을 위해 활성화 레이어 다음에 첨부를 하지만 제안 기법에서는 글로벌 모델 하위 집합에서 직접 선택한다고 한다. 그렇기 때문에 Scaler 모듈을 sBN 이전에 둔다고 한다.
Scaler 모듈은 훈련 기간동안 $\frac{1}{r^p-1}$로 표가된다고 한다. 글로벌 집계가 끝난 이후 글로벌 모델은 스케일링 없이 inference가 이루어진다. 논문에서는 appendix에 테이블 4,5에 이를 추가해두었다고한다. HeteroFL에서는 스케일링 과정을 다음 수식과 같이 나타낼 수 있다고 한다.
$$y=\phi(\mathrm{sBN}(\mathrm{Scaler}(X_mW_m^p+b_m^p)))$$
$y$는 output, $\phi$ 는 non-linear activation layer, e.g ReLU(), $W_m^p, b_m^p$는 weight 와 bias 를 의미한다. Alogorithm 1에서 pseudo code를 설명한다.

알고리즘 1을 보면 먼저 Input 의 값은 다음과 같다.
- Data $X_i$
- $M$ 개의 Local Client
- active client per communication round $C$: 걍 라운드 별 학습에 "참여할 수 있는" 클라이언트 비율을 말하는 듯
- local epoch $E$
- Batch size $B$
- learning rate $\eta$
- global model parameterized $W_g$: 글로벌 모델을 행렬 혹은 텐서로 나타낸 것
- channel shrinkage ratio $r$ 여기서 channel shrinkage라는 것은 뭐 무선통신에서의 그런 채널을 의미하는게 아니라 그 scale에서 축소되는 비율을 의미하는 듯 싶다.
- number of computation complexity level $P$

- 각 라인바이 라인을 보면 먼저 첫번째 글로벌 파라미터를 초기화
- 정해진 communication round를 iteration, rount 변수 $t$
- 해당 라운드에서 참여 가능한 클라이언트를 확인하여 $M_t$에 넣기
- Client selection
- 선택된 클라이언트 서브set에서 병렬적으로 수행
- 선택된 복잡도 $p$ 선택
- 당 p에 대라 가 글로벌 모델 텐서의 채널을 조절
- 해당 채널 크기로 해당 클라이언트의 모델을 설정
- 이후 ClientUpdate(학습)을 수행
- 모든 학습이 끝나면 복잡도 레벨 p에 대해서 점차 모델의 복잡도를 올려가며 집계
- 집계가 끝난다면 해당 글로벌 모델 전체를 업데이트
가 알고리즘 1의 전체 흐름도이다. Client Update의 경우 걍 모델의 학습이라 추가로 작성하지는 않겠다.
4. Expreimental Results
해당 논문에서는 해당 메소드의 검증을 위하여 아무튼 많은 수의 모델과 데이터 셋을 이용하여 학습하였다고 한다. MNIST, CIFAR10, WikiText2 등 아무튼 다양한 거 사용함. 일반적인 BN 대신 sBN을 사용함, 100개의 클라이언트에서 $C$를 라운드별로 0.1 의 fracton을 설정하였다. (10퍼만 썼다는 의미인듯) 데이터 분포의 경우는 각 클라이언트에 동일한 데이터 수의 레이블을 할당한 IID-partion, 두개의 레이블을 가지고 클래스당 데이터 수가 균형을 이루는 것과 왜곡이 되어 있는 두가지 케이스를 설정함. 뭐 데이터 설정에 대한 자잘한 정보는 그냥 읽으면 될 것 같다.
HeteroFL의 효과를 연구하기 위해서 채널 축소 비율(shrinkage ratios) 를 $r=0.5$로 설정함. 그래서 비율은 $a$에서 $e$까지 각각 $\{ 0.5, 0.25, 0.125, 0.0625 \}$ 이렇게 구성됨 복잡도가 logistic regression model에 가까움. 클라이언트에 할당된 계산 복잡도 수준이 고정적으로 할당된 실험의 경우 Fix, 통신 라운드에서 계산 복잡도 수준을 동일하게 샘플링하는 경우를 Dynamic이라고 주석을 달았다고 함. 모든 테이블은 Dynamic 시나링를 기반으로 하며 클라이언트의 모델 복잡도 할당을 무작위로 변경하고 weak learner의 비율을 50%로 고정했다고 한다. weak learner가 뭔진 나도 몰겠다. 아마 단순한 모델을 의미하는 듯 싶다.
그림의 X축은 평균 모델 파라미터를 나타낸다고 함, 10%의 클라이언트는$a$를 90%는 $e$를 사용할때 모델 파라미터의 평균 수는 $0.1 \times$ (size of model 'a') $+ 0.9 \times$ (size of model 'e') 다양한 계산 복잡도 수준을 가진 클라이언트의 비례효과를 보여주기 위해 이 분할을 10%에서 100%까지 단계 크기 10%로 보간한다고 한다.
나타날 결과 fig에서 모델 a-b-c-d-e는 통신 라운드에서 모든 활성 클라이언트에 대해서 균일하게 샘플링한다는 의미임. 논문 비교를 위하여 base라인으로 FedAVG, LG-FedAVG와 비교를 수행함.

결과 그래프에 대해서는 혼자 좀 더 봐야할 것 같다..
'AI,ML' 카테고리의 다른 글
| NLP - [4] Seq2Seq, Attention (0) | 2024.09.24 |
|---|---|
| NLP - [3] LSTM RNN (1) | 2024.09.23 |
| NLP - [2] Language Model, RNN - (3) (0) | 2024.07.21 |
| NLP - [2] Language Model, RNN - (2) (0) | 2024.06.21 |
| NLP - [2] Language Model, RNN - (1) (1) | 2024.06.17 |



