지난 2, 3번 글에서는 단순한 Vanila RNN과 LSTM RNN에 대해서 이야기했다.
CS224n 강의에서 Seq2Seq가 나오는 부분에 앞서서 기계 번역에 대한 내용도 다루고 있는데 해당 내용은 딱히 글에 쓰지는 않고 이번 글은 Seq2Seq과 Attention 매커니즘에 대해서 간단히 알아보고자 한다.
Seq2Seq
seq2seq는 조건부 언어 모델 (Conditional Language Model)의 한 종류이다. 그럼 조건부 언어 모델이 뭐냐 하면 우리가 지금까지 해온 언어 모델들은 아무런 기반을 하지 않고 문장을 생성한다. 즉 언어 모델이 문장 $y$가 나올 확률 $p(y)$를 구하는 방식이었다. 하지만 Seq2Seq는 Source sentence 가 주어졌을때 Target sentence를 예측하는 방식으로 이루어진다. 즉 $P(y|x)$ 를 구하는 방식이다.
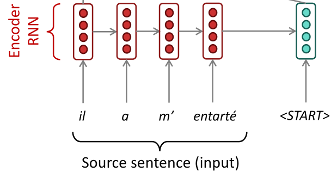
다른 말로 Encoder-decoder라고도 한다. 아래의 예시 그림은 Seq2Seq 구조의 한 예이다.

Source sentence를 RNN을 통해서 문장을 인코딩하고, 이렇게 인코딩 된 문장 표현을 RNN을 통하여 디코딩한다.
위의 그림은 RNN으로 나타나 있는 예이지만 실제로 Seq2Seq는 인코더 디코더로 어떠한 신경망을 가지고 구성해도 된다.
이런 Seq2Seq 모델은 다양한 작업에서 사용 가능하다. Seq2Seq가 가장 많이 쓰는 부분은 기계 번역이라고 보면 될 것 같다. 왜냐면 기계 번역은 원본 언어($x$)가 주어졌을때 번역할 언어($y$)로 번역하는 구조이기 때문이다. 그 외의 부분은 아래와 같다.
- Summarization (Long text가 주어졌을 때 Short text을 output으로)
- Dialogue (Previous utterances 즉 이전 발화가 주어졌을 때 next utterance를 output으로)
- Parsing (text 문장을 주어지면 parsing)
- Code generation (문장이 주어지면 python code로 돌려주기)
Seq2Seq 구조의 학습은 single system으로 최적화 되고 End-to-End로 학습된다고 한다. 아래의 그림을 참조하자

Seq2Seq bottleneck problem
RNN을 이용한 Seq2Seq를 사용하면 가장 큰 문제로 bottleneck problem이 있다. 왜냐면 RNN은 하나의 hidden state에 정보를 계속 재사용/재작성하기 때문이다. 그렇다 보니 문장이 길어지면 한정된 차원의 hidden state에 모든 정보를 넣기 힘들다.
그럼 어떻게 해야 할까? 하나의 hidden state보다 원본 문장에서 정보를 얻어갈 수 있다면 더 나은 결과를 얻을 수 있어 보인다.
이를 이용한 Idea가 Attention이다.
Attention
Attention 즉 주목의 Core idea는 각 step마다 direct conenction을 encoder에 사용하여 얻은 hidden state 즉 source setence로부터 정보를 얻어온다. 예를 들어 아래의 상황을 가정해 보자
Encoder를 사용하여 문장에 대한 표현 (hidden state, condition)을 생성한다. 그리고 Condition을 input으로 하여 start 한다.
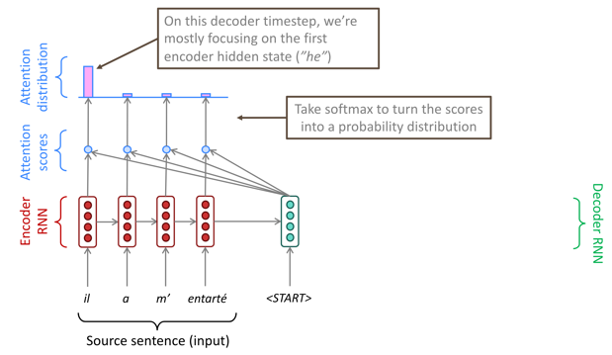
각 위치에서 decoder의 hidden state와 encoder로부터 얻은 모든 hidden state들 간 dot product를 이요하여 Attention score를 생성한다.

두 벡터 간의 dot product이므로 어떠한 실수 값이 나올 것이다. 그럼 이 실수 값을 가지고 softmax를 취하여 Attention distribution을 구한다. 이 Attention distribution에서 가장 큰 값을 가진다는 것의 의미는 decoder의 timestep에서 해당 hidden state에 대해서 가증 큰 focusing을 가진다는 의미가 될 것이다.
이러한 확률 분포를 이용하여 Attention output이라는 Attention 분포를 기반으로 한 hidden states의 가중 평균을 구한다.

이렇게 구한 Attention output과 decoder의 hidden state를 통하여 $\hat{y_1}$를 계산한다. 그리고 이런 일련의 과정을 계속 반복한다.
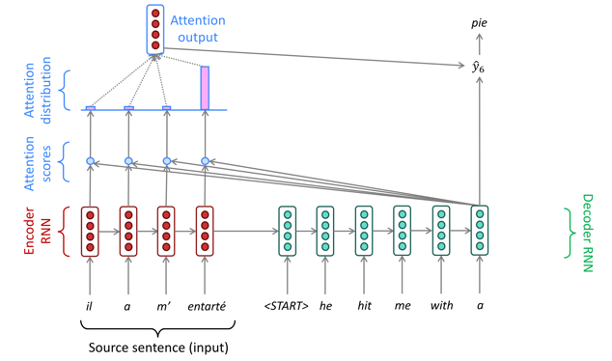
이렇게 Seq2Seq구조에 대해서 알아보았고 다음 글을 마지막으로 NLP에 대한 cs224n 내용 정리를 마무리하려고 한다.
마지막 글의 주제로는 Attention을 이용하여 새로운 Architecture를 어떻게하면 구성할 수 있을지 그리고 이렇게 만들어진 Attention architecture를 기반으로 Transformer 구조를 알아보고 마무리 하겠다.
참조 문헌
https://youtu.be/wzfWHP6SXxY?feature=shared
'AI,ML' 카테고리의 다른 글
| HeteroFL: Computation And Communication Efficient Federated Learning For Heterogeneous Clients (1) | 2024.12.02 |
|---|---|
| NLP - [3] LSTM RNN (1) | 2024.09.23 |
| NLP - [2] Language Model, RNN - (3) (0) | 2024.07.21 |
| NLP - [2] Language Model, RNN - (2) (0) | 2024.06.21 |
| NLP - [2] Language Model, RNN - (1) (1) | 2024.06.17 |



